Surveillance and security in traditional sense is now moving forward – in leaps and bounds. Gone are the days when people were using analog cameras. Analogs are rapidly being replaced by digital cameras which enable video analytics to perform on an incoming digital stream. Also, between 2005 and 2010, there was a massive push to standardize the interface between the camera, and the software that talks to it over an ethernet cable. ONVIF – the Open Network Video Interface Forum – meant to provide and promote standardized interfaces for effective interoperability of IP-based physical security products, laid these standards. (Though many camera manufacturers claim that they are ONVIF compliant – one must check onvif.org to confirm). That development disrupted the stranglehold of camera manufacturers with their partners and allowed many other players to enter into the market as proprietary protocols were no longer required.
Most of the terabytes of stored video is useless as it does not carry any useful information. Manual searches need to be conducted to find the relevant information one is looking for. This turns out to be a time-consuming process, as well as by the time information is found it might be out of date. This is where video analytics comes in fray which helps to some degree by looking for only relevant information – thereby saving time and resources. (https://www.securitylinkindia.com/feature/2019/09/11/actionable-video-intelligence/). Even though video analytics saves a considerable amount of time, it still does not avoid the manual process involved in looking at video instead of data.
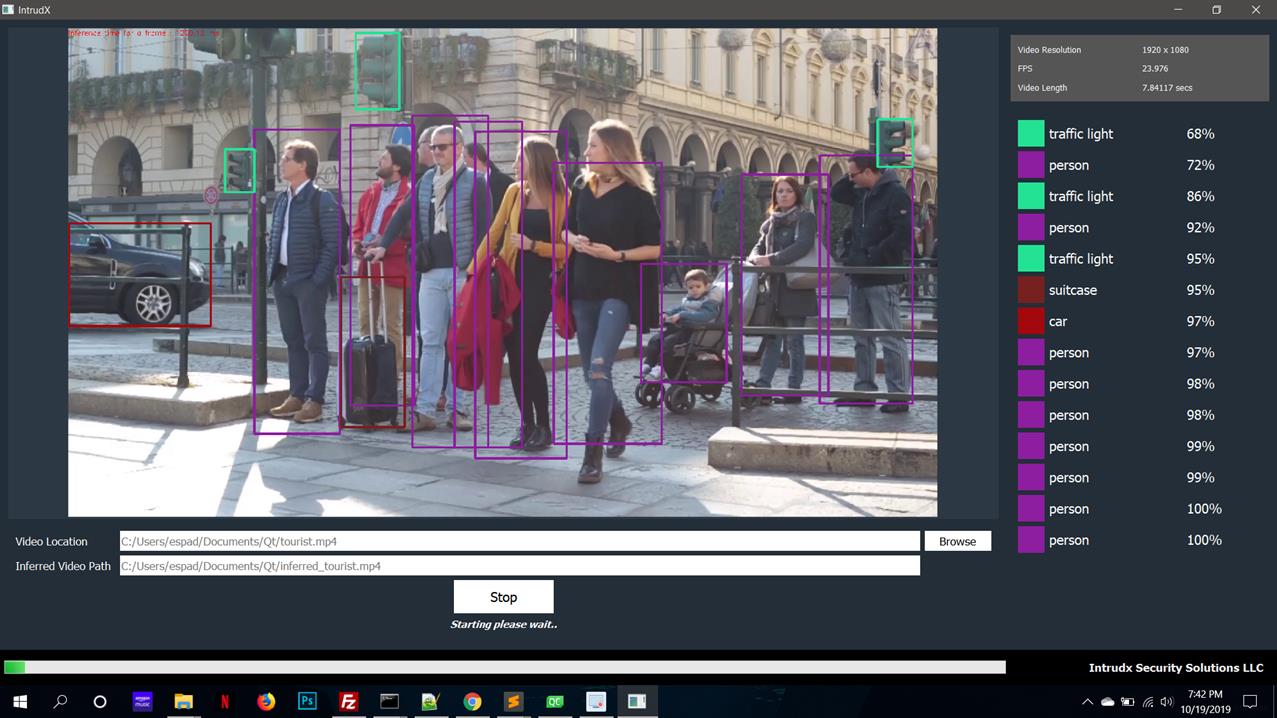
Now at this point – artificial intelligence and machine learning are meant to come in. Artificial intelligence builds a model based on a few initial parameters that are input by the user. Without getting into the details, it quickly builds a neural network and tells the confidence level of each object found in the video frame. This is a highly mathematical process involving convolution, calculus, probability and statistics. Based on the confidence level of each object found in the frame, one can fine tune the neural network by changing the input parameters. This fine tuning is called Machine Learning by which the neural network raises the confidence levels above 95% for each object found. We have done this in our ‘intrudX’ product whereby object confidence levels go from as low as 60% to as high as 98%. One can now put the neural network in training mode telling it the target end result a user wants. The machine can self-learn by varying hundreds of input parameters till the end target is met, and at this stage the user gets the model what he has been expecting. He now continues to use this highly accurate model to build his applications to solve problems specific to their market vertical.
So, what have AI/ ML done? They eliminated the requirement of video examination – now, only the extracted data from the video stream is examined. This is a far more intelligent way of examining video streams in a far more efficient way – allowing the end user to build multiple intelligent applications on top of this. This is the ‘wave’ of the future as multiple petabytes of data cannot be examined after this fact. With the number of cameras exponentially increasing all across the globe, the best way to process video is on the fly – in real time – as it saves time, money and resources across the board. However, some time and money have to be invested for a particular use case to fine tune the neural network model. Once this process and methodology are mastered, one can use it for other use cases as well.
In our case, some of ‘intrudX’ models took up just 30 minutes to bring up the confidence level above 95%, while in other cases it has taken even a week.
Factors that affect the training period are:
- Lighting,
- Number of objects in the frame, and
- Complexity of the shape of the object.
A couple of used cases are described hereunder to make this concept clear.
USED CASE I
Implementing standard operating procedure (SOP)
While defining SOP for a drug testing methodology in a pharmaceutical laboratory – following are the requirements:
- Capturing and time stamping when an employee enters and exits the laboratory.
- Measuring the procedure when the drug testing starts.
- Identifying colored flasks and test tubes, and their movement from one step to the next.
- Identifying the microscopes and other medical instruments used in the measurement and how they are being used.
- Flagging the deviation, if any, from SOP and report it to the administrators.
Obviously, one can use identifying objects in the video stream and determine whether the SOP is being followed or no. This can be used by the laboratory management team to improve overall efficiency of the laboratory and its’ employee performance without looking at the video streams.
USED CASE II
Measuring queue lengths
While measuring queue lengths at bank counters, airport check-in lines, hospitals etc – requirements are as follows:
- Determine queue lengths to fix arrival and service rates.
- Queue lengths will increase if service time is greater than the person’s arrival time.
- Flag these so the service efficiency can be improved
Summary
The neural network model has over 25 million pre-defined objects in the database which have been developed using artificial intelligence techniques. In a typical end user case a very small subset of these 25 million predefined objects is required. New objects are continuously being added to the database. The model also allows itself to be put in training mode based on what the end user really wants.
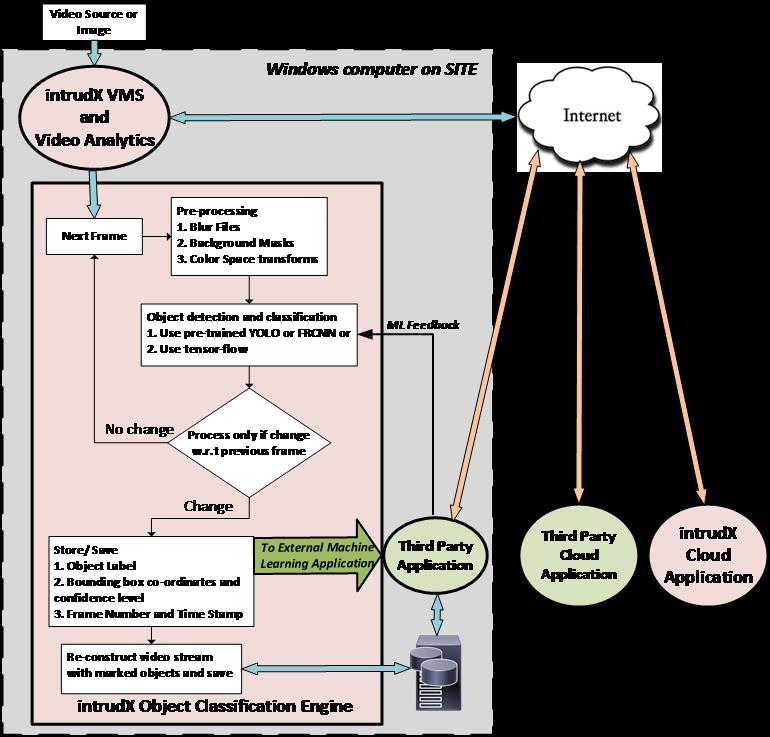
‘intrudX’ Object Classification Engine takes advantage of this feature and provides interfaces so that end user case applications can be developed rapidly and be put to use. We provide extracted data, interface to the ML neural network model, as well as application development services for the customer.

By- Paresh Borkar,
Founder & MD,
intrudX Security Solutions, LLC
![]()